工作站使用指南
欢迎使用Pisces工作站。此工作站为部分组内成员提供计算服务。 在使用工作站之前,如果你没有使用集群进行计算的经验,那么我们强烈推荐你花费一点时间 来阅读此说明书上的内容。这些内容也可不必在很短时间全部看完,不过快速入门的 部分还是要仔细看一下,这是工作站指南的一个简化版,非常适合无基础的用户学习。
我们选择工作站进行计算的理由是
-
它可以将我们的个人电脑从繁重的任务中解放出来。利用工作站,你可以运行更大规模的程序。 在此期间你可以用你的个人电脑做其他的事情,甚至关机,都不会影响工作站的进度。
-
它在并行计算方面有极大的优势。工作站服务器的处理器特点是核心数量很多,虽然每个核心 的运算能力不算最强,但是协同工作时会提供很高的加速比。
-
它可以加深你对软件运行环境的理解。从而会让你产生编写可移植性更强的程序的意识。
工作站概况
计算配置:
| 节点类型 | 节点数量 | 详情 | 总CPU核心 | 内存 | 备注 |
|---|---|---|---|---|---|
| CPU | 1 | 2 x E5-2667 v4@3.20GHz, 8 cores | 16 | 256 GB | — |
| 节点类型 | 节点数量 | 详情 | 总GPU核心 | 显存 | 备注 |
| GPU | 1 | NVIDIA 1080Ti x 2 | 3584 x 2 | 11 GB x 2 | cuda 9.0 |
其他配置:
| 名称 | 详细说明 |
|---|---|
| 存储 | 18 TB 存储空间,暂无磁盘配额。+ 40TB NAS |
| 网络 | 对台内 1 Gbps。 |
| 系统 | Ubuntu 17.10 |
快速入门
如果你想快速学习如何使用我们的工作站,请阅读这个部分。
在你看了工作站的简略介绍之后,或许你已经有兴趣想在工作站中试着运行你自己的程序。
获取你的账号
我们的工作站只允许已经授权的用户进行登录。在从管理员处获得你的账号名和初始密码后, Linux 或 Mac 用户可直接从命令行登录我们的工作站,使用 ssh 命令即可
1 | $ ssh username@ip_address |
请将 sername 和 ip_address 替换为管理员提供的参数。
成功连接后,服务器会提示你输入密码,此时请输入初始密码。输入密码的时候界面不会有 任何反应,但是密码已经输入进去了。
致 Linux 初学者
服务器的系统是 Linux,本文档假设用户有一定的 Linux 基础。不熟悉 Linux 基本操作 的用户(例如查看文件,编辑文本,复制数据等)可以先花一些时间熟悉这些操作,本文档除特殊需要以外不再单独讲解 Linux 的操作。
致 Windows 用户
由于在服务器上的操作大多基于 Linux,如果能在 Windows 下能使用相同或相似的操作 会给用户带来很大方便。下面提供了几种 Windows 用户的主要使用方式,用户可以自行 选择。
-
使用 WSL(Windows Subsystem Linux)。WSL 是新版 Windows 10 的特性,它可使得用户 在 Windows 系统下运行命令行模式的 Ubuntu 或 OpenSUSE 等子系统。使用 WSL 的用户 可直接使用文档中的 Linux 部分。强烈推荐对图形界面需求不大的用户使用。具体安装 方式可以参考微软的安装 WSL 教程。 安装时请留意自己的 Windows 版本。此方式的缺点:终端模拟体验不好;图形界面配置 麻烦。
-
使用虚拟机安装 Linux。如果不想安装 Linux 双系统可以选择使用这种方式。正确配置 的虚拟机和真正使用 Linux 几乎无差别。虚拟机用户可直接使用文档中的 Linux 部分。 并可以使用服务器的图形界面。网络上有关虚拟机的教程非常多,在此不一一列举。 虚拟机软件推荐 Windows 10 自带的 Hyper-V 和 VMWare。此方式的缺点:虚拟机启动 时间长;完全启动时占用系统资源较多。
-
使用 PuTTY 等 SSH 客户端。Windows 10 以下的用户可以使用这种方式。SSH 客户端 提供了较完整的 SSH 功能。
准备你的程序
在成功登录之后,你可以测试你的第一个服务器程序了。不过在这之前,你需要在服务器上 准备好你的程序。可以临时书写或者是从本地计算机上传。
假如我在本地编写了一个名为 hello.c 的 Hello World 程序,我要将其上传到工作站上, 那么我将会在本地计算机上使用 scp 命令进行远程复制。
1 | $ scp hello.c username@ip_address |
这个命令将本地当前目录的 hello.c 上传到了工作站的 HOME 目录下。复制的过程中需要 输入我的密码。以上的命令适用于 Linux 或 Mac 系统。有关更详细地在工作站和个人电脑 之间传输文件的说明可以在这里查看。
小提示
- 程序所需要的数据也可用 scp 命令进行上传。
- 当你设置了免密码登录时,会更为方便
指定运行环境
程序源码准备完毕后,你需要为你的程序搭建其所需的运行环境。例如准备相应的库以及 编译成可执行程序等。不建议将本地编译好的程序直接上传。如果你是 python 用户,则你只需要指定 python的版本就可以了。
在这里,我上传了一个 C 源码,因此我需要检查我的编译器是否满足需要。
1 | $ gcc -v |
确定了编译器版本之后,我还要确定所需要的库。因为我这里只是一个 Hello World 程序,所以 暂时用不到特殊的库。不过,运行实际的程序可就不会这么简单了,必须要检查对应的库在 系统中是否存在。
对于我现在的情况,只需要执行很简单的一步编译命令即可
1 | $ gcc -o hello hello.c |
登录集群服务器
使用工作站之前,你必须拥有一个工作站账号才能进行任务提交。申请工作站账号请联系工作站管理员:
miaocc@nao.cas.cn
使用Linux/Mac OS
使用这两个系统的用户推荐用终端远程登录到工作站服务器。
Linux : CTRL+ALT+T
Mac OS : Finder->应用程序(Applications)->实用工具(Utilities)->终端(Terminal)
之后使用如下命令:
1 | $ ssh username@ip_address -X |
'$'为 Shell 提示符,无需输入。username 为你的用户名,ip_address 是我们的服务器 IP 地址,-X 是开启 X11 Forwarding,此功能用于使用图形界面,如果不需要此功能可以不填写。
输入你的密码,如果出现以下界??表示登录成功。此后可以在此终端里面进行工作站的操作。
注意:输入密码时,终端的输入区域不会显示任何字符,但是密码已经输入进去了。
成功登录后,所在路径为个人的 Home 文件夹,绝对路径为/ssd/用户名 ,你可以任意访问和修改个人文件夹下的所有内容。
想要登出工作站时,执行下面的命令。不要直接关闭终端。
1 | $ exit |
初次登录时,系统会强制你修改密码,请务必设置复杂一点的密码,修改完毕后重新登录。
如果想要再次修改密码,请使用下面的命令。同样,更改密码时终端输入区域不会显示任何字符。
1 | $ passwd |
使用Windows
在 Windows 操作系统中,你需要使用任意一种 ssh 客户端来远程登录到工作站服务器。 建议使用 PuTTY 客户端。
安装完毕后,按照如下的方式远程登录工作站(使用方法以 PuTTY 为例):
- 打开 PuTTY 客户端。
- 输入IP地址(Host Name),端口号默认为 22。
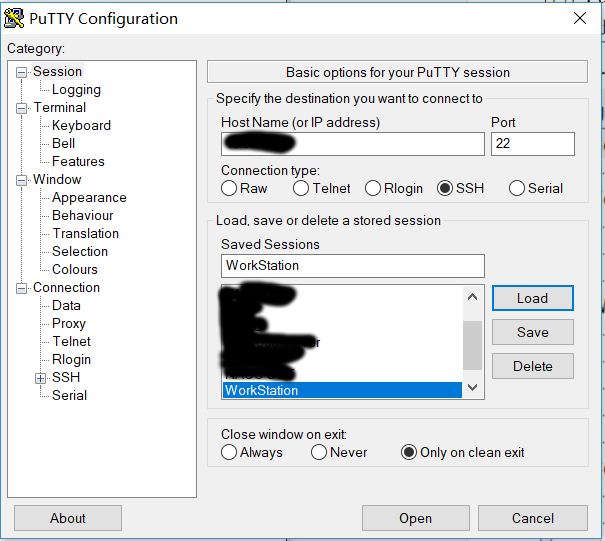
输入完毕后,建议保存当前的 Session 信息。
- 输入用户名和登录密码。
- 如果出现以下界面表示登录成功,此后可以在此终端里面进行工作站的操作。
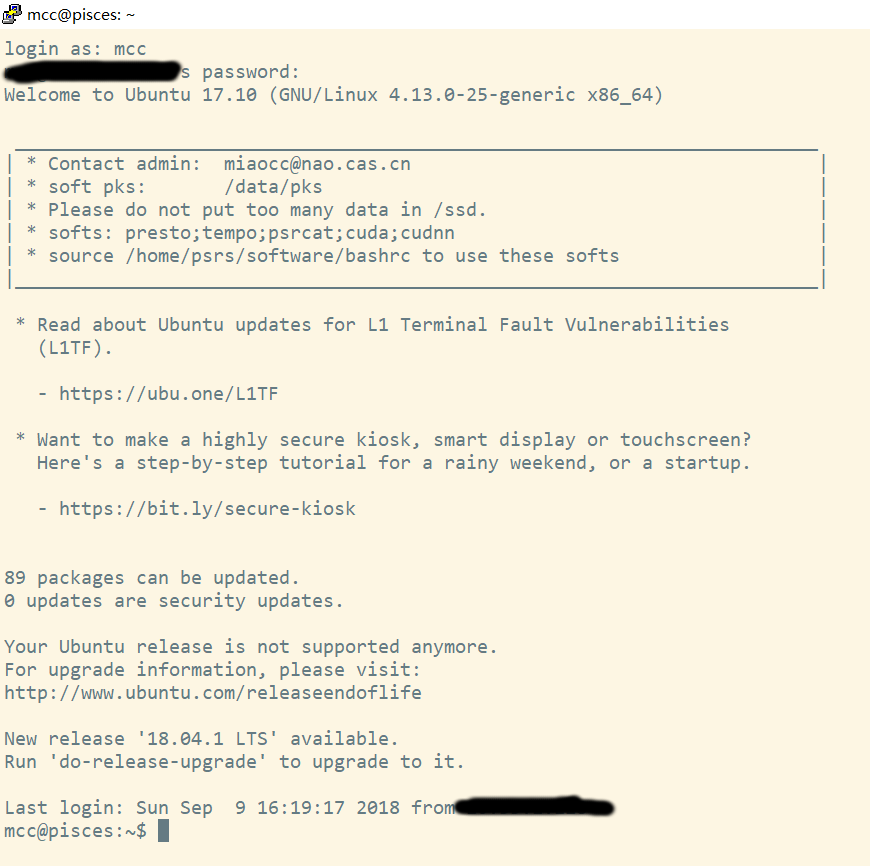
想要登出工作站时,请输入如下语句。不要直接关闭 PuTTY。
1 | $ exit |
初次登录时,系统会强制你修改密码,请务必设置复杂一点的密码,修改完毕后重新登录。如果想要再次修改密码,请使用下面的命令。同样,更改密码时终端输入区域不会显示任何字符。
1 | $ passwd |
配置 SSH
使用Linux/Mac OS
配置 .ssh/config
每次连接服务器都要输入用户名和服务器地址似乎有些麻烦,如果可以记录不同 SSH 配置 会给使用带来很大方便。在这里我们需要借助 .ssh/config 这个文件。
首次使用 SSH 时,本地计算机中是没有这个文件的,我们必须手动创建它。
1 | mcc@pisces:~$ cd ~ # 进入本地用户 HOME 目录 |
创建完毕后,在 .ssh/config 中添加如下内容:
1 | Host rule-name |
以上配置的含义是,配置一个名称为 rule-name 的匹配规则,服务器地址是 xxx.xxx.xxx.xxx,使用的服务器用户是 user,访问 22 端口。设置的时候需要 把以上内容替换成真实的信息。其中规则的名称可以随便起。
成功配置后,假设我的 rule-name 设置为 pisces,那我下次登录只需要执行
1 | ssh pisces |
则 SSH 客户端就会在 .ssh/config 文件中匹配对应的规则,而后套用登录参数, 从而达到省略用户名和 IP 地址的目的。此配置对 OpenSSH 的其他程序也生效。 例如使用 scp 时也可以用这个配置
1 | scp pisces:a.txt . |
这会将目标服务器 HOME 目录下的a.txt 复制到当前目录,非常方便。
如果你有多个服务器,只需要在 .ssh/config 文件中用空行将不同规则隔开即可。
几点说明
-
规则名称可以使用通配符 *,例如 Host * 表示和任意规则匹配。这种配置的用处 是为其他不匹配的规则设置默认值。由于匹配是从上而下进行,这条配置一般出现在 config 文件的末尾。
-
在命令行直接指定的参数会覆盖
config中对应的值。例如,config文件设置了User mcc,但在命令行执行ssh root@Pisces,则config文件中的相应配置失效,但其余配置(例如 IP 地址,端口等)依然有效。
配置无密码登录
配置 .ssh/config 之后,我们每次使用还是要输入密码。然而我们不能把密码写在 config 文件 里,而需要使用 SSH 密钥来完成无密码登录。这种无密码授权仅对你自己的个人计算机 有效,别人是无法登录你的服务器账号的,所以请放心使用。
首先,请在本机命令行中输入以下语句来生成 SSH 密钥对(如果之前生成过就无需执行 此步骤,否则可能会覆盖之前生成的密钥):
1 | $ ssh-keygen -t rsa -b 4096 |
其中 -t rsa 表示使用 RSA 算法;-b 4096 表示加密位数是 4096,位数一般是 2 的幂次,越大则加密强度越高。生成过程中,系统会询问你 SSH 密钥对的保存位置,以 及对应的密码等。在这里我们使用默认的保存位置,不对 SSH 密钥设置密码。 因此只需要连续点击三次 Enter 即可。
生成好的密钥对会保存在默认目录 $HOME/.ssh/ 下,文件 id_rsa 和 id_rsa.pub 就是刚刚生成的密钥对。请将 id_rsa.pub 文件复制到服务器端(可使用 scp 命令), 复制的过程中需要输入你的密码。
此外,请保管好 id_rsa 文件,不要将其复制给他人。
最后,登录到服务器端,输入登录密码,进入到 id_rsa.pub 文件所在的目录下,输入以下命令:
1 | $ cat id_rsa.pub >> ~/.ssh/authorized_keys |
至此,SSH 无密码配置已经完成。下次登录或者远程复制时系统不会提示你输入密码。
建议在配置结束之后确认一下服务器端的文件与文件夹的权限。正确的配置是 .ssh 文件夹的权限为 700,即仅所有者拥有完整的权限;.ssh/authorized_keys 文件的权限为 600,即仅所有这拥有读取和写入权限。
1 | [mcc@pisces ~]$ ls -dl .ssh; ls -l .ssh/authorized_keys |
使用Windows
首先,使用 PuTTYGEN 程序(该程序和 PuTTY 在同一个压缩包内)生成 SSH 密钥。
生成完毕后,请务必点击 Save Private Key 将密钥保存下来,密钥的格式为 ppk,可以不设置密钥的密码。
对于已经存在的 ppk 密钥文件,可以用这个工具打开并查看该文件的公钥部分(上图中最上面 ssh-rsa 开头的一长串文字)。
然后,你需要使用密码登录服务器,将上述图中公钥部分粘贴到 $HOME/.ssh/authorized_keys 文件的末尾。
最后你需要完成本地的登录设置。打开 PuTTY 程序,载入你要使用 SSH key 的 Session 进行导入。点击左侧的 SSH -> Auth,在右侧选择刚才存储的 ppk 密钥文件。
保存当前的会话设置,这样可以永久生效。
配置运行环境
我们的工作站服务的环境需要用户自主配置bashfile。
服务器安装了一系列脉冲星所需要软件及其他相关软件。
假如用户想要调用这些环境,需要对用户目录下的.bashrc进行编辑。
将以上软件全部增加到环境变量里面,在.bashrc最后加上:
1 | if [ -f /home/psrs/software/bashrc ]; then |
然后运行source ~/.bashrc重载环境变量。
常见问题
在使用服务器的时候你是否也有一些疑问?这些问题可能已经被问过很多次,所以不妨在这里 寻找一下你的答案。
Q:登录服务器时,输入密码时终端无反应。
A:这是正常现象,请正常输入你的密码然后按下[Enter]登录即可。
Q:如何在服务器和本地计算机之间传输文件?
A:可以使用 scp 或 WinScp 等工具。
Q:我如何才能保存计算过程中控制台中输出的结果?
A:请使用输出重定向符号‘>’。例如将程序 text 的控制台输出重定向到文件 ‘out.txt’ 中
1 | ./test > out.txt |
Q:工作站的联网情况如何?
A:能够访问国内绝大多数网址,不能够访问某些国际网址(例如 google.com )。 由于我们的 IP 是固定的,并且只有内网地址,所以外网用户无法登陆或者需要进行跳转。
Q:为什么我在自己的机器上无法登录账号,启动 SSH 连接时显示超时。但是使用别的机器就可以登录?
A:为了服务器的安全,当同一个设备连续登录失败 5 次以上时,该设备的 IP 将会被封禁 24 小时,无法从 此 IP 地址登录。遇到这种情况请及时联系管理员解封。另外,配置 SSH 无密码登录是一个好习惯。
Q:我可以在服务器上安装服务器上没有的软件吗?
A:可以。需注意的是,绝大多数软件的安装不需要管理员(root)权限,为此,你可能无法像使用你的个人计算机那样使用 apt/yum 进行软件的安装。
- 一般的开源软件可以直接从源码编译安装,一个详细的例子:从源码安装 FFTW
- 安装属于自己的 python 或 R 包可以参考下面的方式:
- 安装 python 包到个人目录
- conda 入门教程
- virtualenv
软件安装完毕后,需要根据软件配置自己的环境变量。自行安装的软件可以被别的用户使用。
Q:用 conda 或 pip 下载 python 包很慢怎么办?
A:请使用清华镜像源。具体方式请查看链接。(https://mirrors.tuna.tsinghua.edu.cn/help/pypi/)切记要激活使用的python虚拟环境再安装。
集群软件
为了方便同学运行程序,集群中安装了许多类型的软件。这些软件都在管理员维护的范围内,如果 有新的需求,也可联系我们来安装所需的软件。
目前已经安装的大部分软件列表:
- PSRCAT
- tempo
- psrcat
- PGPLOT
- cfitsio
- psrchive
- cudnn-9.0
- cuda-9.1
- docker
- NVIDIA driver-387.34
- gcc-5.4
- g++-5.4
- gfortran-7.2
- python2.7
python 虚拟环境软件
python 虚拟环境软件也不少,在集群上可以使用如下的两种方式,分别是anaconda和virtualvenv。两种软件各有千秋,但是anaconda在部分的集群使用的时候可能会干扰vnc。
virtualvenv
你在开发中很可能想要使用 virtualenv,如果你拥有生产环境的 shell 权限, 同样会乐于在生产环境中使用它。
virtualenv 解决了什么问题?如果你像我一样喜欢 Python,你会拥有很多项目,但是你拥有的项目越多,同时使用不同版本 Python 工作 的可能性越大,或者至少需要不同版本的 Python 库。我们需要面对的是:常常有库会破坏自身的向后兼容性, 然而正常应用零依赖的可能性也不大。当你的项目中的两个或更多出现依赖性冲突时,你会怎么做?
virtualenv 来拯救世界!virtualenv 允许多个版本的 Python 同时存在,对应不同的项目。 它实际上并没有安装独立的 Python 副本,但是它确实提供了一种巧妙的方式来让各项 目环境保持独立。让我们来看看 virtualenv 是怎么工作的。
如果你在 Mac OS X 或 Linux下,下面两条命令可能会适用:
1 | $ sudo easy_install virtualenv |
或更好的:
1 | $ sudo pip install virtualenv |
上述的命令会在你的系统中安装 virtualenv。假如发现安装之后不能够使用,记得更新一下你的python环境。它甚至可能会存在于包管理器中,如果 你使用 Ubuntu ,可以尝试:
1 | $ sudo apt-get install python-virtualenv |
如果你所使用的 Windows 上并没有 easy_install 命令,你必须先安装它。查阅 Windows 下的 pip 和 distribute 章节来了解如何安装。之后,运行上述的命令,但是要 去掉 sudo 前缀。
virtualenv 安装完毕,你可以立即打开 shell 然后创建你自己的环境。我通常创建一个 项目文件夹,并在其下创建一个 venv 文件夹
1 | $ mkdir myproject |
现在,无论何时你想在某个项目上工作,只需要激活相应的环境。在 OS X 和 Linux 上,执行如下操作:
1 | $ . venv/bin/activate |
下面的操作适用 Windows:
1 | $ venv\scripts\activate |
无论通过哪种方式,你现在应该已经激活了 virtualenv(注意你的 shell 提示符显示的是 活动的环境)。假如在bash脚本中想要使用这个环境,只要将python环境设置为#!~/venv/bin/python就可以了。
conda & pip
为 conda 和 pip 添加镜像
由于国内访问 repo.continuum 和 pypi 的速度较慢,用户可自行设置清华镜像,会 极大提高下载速度(不会提高环境解析速度)。
- conda: 清华镜像,里面还 包含 pytorch 等第三方源。
- pip: 清华镜像
conda 在解析环境时,由于要将所有 channel 扫一遍,在遇到 repo.continuum 时 会非常慢。根据清华源的文档设置镜像后,可进一步手动修改 ~/.condarc 屏蔽 默认的 channel (defaults) 以提高解析速度。
$ cat ~/.condarc
1 | channels: |
conda 包&环境管理器
anaconda 中提供的 conda 是包&环境管理器,不只是 python 包管理器。python 包既可以 使用 conda 安装也可以使用 python 自带的 pip 安装。
conda 环境管理器允许用户创建多个隔离环境,注意这里的环境与 module 环境管理不同, 我们所用到的 conda 更多用于管理不同版本的 python 的不同版本的库:env1,env2,…, 允许其中每个 env[1-n]中的 numpy、scipy、torch、tensorflow…版本互不相同, 只需要环境内部保证版本依赖性兼容即可。
例如 A,B 两个库都依赖 C, 但 A 要求 C 的版本不能超过1.0,B 要求 C 的版本超过1.1,这时用户可以按照如下方式设置环境:
-
env0: B & C-v1.1 & 其他常用库
-
env1: A & C-v1.0 & 其他常用库 当用户需要使用 A 时切换到环境 env1,想使用 B 时切换到环境 env0。
这里我们简要介绍一下 conda 作为环境管理器的使用方法,网上也有很多的介绍。
服务器目前 anaconda/3-5.0.0.1 中默认的环境是 base,其中的 tensorflow 版本为1.3.0。 下面我们演示一个例子:普通用户安装一个版本为 1.5.0 的 tensorflow-gpu。
注意:由于我们系统的版本较旧,使用 pip 安装的 tensorflow 依赖高版本 GLIBC 库, 从而无法正常使用。此例子只用来说明如何使用 conda。
查看当前已安装的 conda env
1 | mcc@pisces:~$ module add anaconda/3-5.0.0.1 |
打开 jupyter-console 验证一下当前环境里所用的确实是 tensorflow-gpu 1.3.0,
1 | mcc@pisces:~$ jupyter-console |
使用 conda create -n <ENVNAME> 可以创建一个与原环境相隔离的环境,当用户不具有在原来的 anaconda 中增添一个环境的权限时,这条命令会自动帮用户在 ~/.conda/envs/ 下创建环境。 如下,我们指定新 env 的名字为 tf15,同时指定其初始包为 python,scipy,jupyter, 其中指定python的版本为3.6。
这里注意,conda 是一个完全独立于 python 的包&环境管理器,python 对于 conda 来说 只是 conda 的一个包,就如同 Linux 把 conda 当成一个包一样, scipy、jupyter 对于 conda 来说也都是包 — -虽然 scipy 对于 python 来说 也是一个包,而 jupyter 与 python 则是相互独立的。
1 | mcc@pisces:~$ module add anaconda/3-5.0.0.1 |
现在再执行 conda info –env ,这个用户所独有的名为 tf15 的 env 已经在列表中
1 | mcc@pisces:~$ conda info --env |
使用 source activate <ENVNAME> 可以加载已安装的 env,而使用 source deactivate 退出当前 env。在加载某个 env 之后,命令行前缀会加上这一 env 的名字,在当前 env 下, 所使用的 python,pip 等命令是当前 env 所独有的。
1 | mcc@pisces:~$ source activate tf15 |
我们可以用当前环境的 pip 安装 tensorflow-gpu 的1.5.0 版,这个版本的预编译版使用 cuda 9.0, 由于当前环境所在目录就在我的个人目录 .conda/envs 下,我已经有当前环境的读写权限, 因此在使用 pip 时并不需要 --user 参数。相信很多用户已经试过,如果在 base 环境下执行 pip 会遇到 PermissionError 的问题,原因是 base 环境并不属于普通用户,在 base 环境下需要增加 --user 参数。
1 | (tf15) mcc@pisces:~$ pip install tensorflow-gpu==1.5.0 |
现在打开当前 env 的 jupyter-console 验证一下 tensorflow 的版本:
1 | (tf15) mcc@pisces:~$ jupyter-console |
最后,使用 source deactivate 退出当前 env。顺便,如果你发现自己的某个 env 不想用了 可以用 conda env remove -n <ENVNAME> 来删除这个环境。
1 | (tf15) mcc@pisces:~$ source deactivate |
常用命令总结
1 | # 创建环境 |
一些说明
我们使用 conda create -n
如果不加这三个初始包,会发生什么?
我们看一下不加python这个包会发生什么。
我们创建一个名为 tmp 的 env,根据默认设定,新环境的所有文件都将放在 .conda/envs/tmp 下, ??于是空的 env,所以不需要联网。
mcc@pisces:~$ conda create -n tmp
加载当前环境,并看一下用的是哪个 python 和 pip
1 | mcc@pisces:~$ source activate tmp |
可以发现,由于没有安装 python 包(重复说明,对于 conda 来说 python 就是一个包, 就好像对于 Linux 来说,conda 也只是一个包而已),python,pip 还是原来环境中的 python 和 pip
这时我们执行 base 环境中的 pip 安装命令,它会尝试安装包到 base 环境中, 自然会遇到 PermissionError 的问题
1 | (tmp) mcc@pisces:~$ pip install tensorflow-gpu==1.5.0 |
用 conda 装上 python,有了自己独立的 pip,再装 tensorflow-gpu==1.5.0,就可以成功了。
1 | (tmp) mcc@pisces:~$ conda install python=3.6 |
同理,如果不安装 jupyter 包,那么在这个环境下使用的 jupyter-console, jupyter-notebook 也将都是原来环境中的 jupyter-console, jupyter-notebook。
最后提一下:如果使用
mcc@pisces:~$ conda create -n <ENVNAME> python=2.7
那么你将得到一个内置 python 2.7 的可用环境,注意到原来的 python 是3.6。
使用VIM
使用 VIM
用好了VIM真的会提高很大效率。
本人并不精通 VIM,还要好多东西要学习。
打开与关闭
1 | # 使用 vim 打开文件,如果文件不存在就新建一个 |
获取帮助
- 功能太多了,看得眼花缭乱。我怎么知道哪一个是我想要的?
- 内置文档。很多人可能不知道这是个什么东西。打开 VIM 后,输入 :help 即可 打开内置文档。这里面的功能最全,在阅读文档的时候还可以顺便练习一下 VIM 的 操作。
- vimtutor: 我又一次提到了这东西。对初学者这东西简直是福利啊。在命令行下 输入 vimtutor 即可打开。
- VIM adventures: 有人居然将 VIM 教程做成了游戏。还不快去玩玩。传送门
- Google。好吧,这也是一个不错的选择。但是前提是你得知道怎么搜。
普通模式
VIM 编辑器有多个模式:普通模式,插入模式,VISUAL 模式。进入 VIM 编辑器后, 编辑器处于普通模式,在此模式下,VIM 编辑器会将按键解释成命令。
h,j,k,l移动光标,分别对应:左,下,右,上。不要总去碰键盘右边的方向键, 尽量熟悉用 hjkl 来移动你的光标。w,b,W,B更快地移动光标到下一个词/上一个词。使用大写字母移动得更快。:q如果未修改数据,退出:q!取消所有修改,退出:wq, :x, ZZ保存并退出,笔者更喜欢用 ZZ,因为只要按三下键盘。:qa!关闭当前打开的所有文件,退出:<数字>直接跳转到指定的行:tabe <文件名>新建或打开一个新文件,并以标签形式显示在编辑器上方gt,gT切换到下一个/上一个标签x删除当前位置字符dd删除当前行(实际是复制到了剪贴板处)<数字>dd删除指定数目的行数diw删除当前光标所在单词d$删除当前光标所在位置至行尾的内容yy复制当前行<数字>yy复制指定数目的行数yw复制当前光标所在单词y$复制当前光标所在位置至行尾的内容p将剪贴板的内容粘贴至当前位置i,a,I,A进入插入模式,并将光标放置在 i: 当前字符前,a:当前字符后, I: 本行第一个字符前,A:本行最后一个字符后。o,O在下方/上方插入空行,并进入插入模式。u,Ctrl-r撤销上一步的更改/重做上一步的撤销。Ctrl-Z暂时离开 ViM 编辑器,回到 Shell 界面。在 Shell 中使用 fg 命令即可返回 VIMCtrl-a,Ctrl-x将光标所在的数字增加/减少 1。注意:考虑进制,若光标所在的 数字当前为 07,则一次 Ctrl-a 过后将会变成 10(因为 07 是八进制)。
插入模式
在插入模式下,即可插入文本到光标的位置。按下 Esc 键即可返回普通模式。
Ctrl-w 删除光标前的一个词。这比按 Backspace 更快。
VISUAL 模式
在普通模式按下 v 可以进入 VISUAL 模式,按下 Ctrl-v 可以进入 VISUAL BLOCK 模式。 两个模式下可对文本进行选择的操作。进而可将普通模式的操作只应用在选择的区域上。
VISUAL BLOCK 模式下批量注释
在没有安插件的情况下,VISUAL BLOCK 模式下可以完成一些简单的批量注释工作。
1 | 按下 Ctrl-v 进入 VISUAL BLOCK 模式 |
查找与替换
普通模式下,可进行查找和替换。
/foo从当前位置向后查找 foo 这个关键词。?foo从当前位置向前查找 foo 这个关键词。n,N跳转到下一个/上一个匹配查找的位置。:%s/foo/bar/将每行的第一个 foo 替换为 bar。:%s/foo/bar/g将所有的 foo 替换为 bar。:%s/foo/bar/gc将所有的 foo 替换为 bar,并在每次替换之前询问。
其他
进入粘贴模式
在设置过自动缩进的 VIM 编辑器下,粘贴模式可以临时取消所有的自动缩进识别。
1 | `:set paste` |
命令行操作
很多初学者可能只会在命令行上用方向键/Home/End 来移动光标,这是 ok 的。不过 当你发现某个很长的命令中间有个词打错了的时候,是选择删掉重新打,还是将光标 移动到出错处更改,这就是个问题了。
- 左右方向键:左右移动,每次移动一个字符。
Ctrl-f,Ctrl-b:左右移动,效果跟方向键一样,但是不会让你的右手频繁移动。- 上下方向键:滚动历史曾经执行过的命令。
Ctrl-a,Ctrl-e:移动到行首/行尾。这样右手就不用大老远去按 Home/End 了。Alt-f,Alt-b:向右/左移动一个词的位置。Ctrl-w:删除当前词。(实际是删除到光标左边最近的一个空格)Ctrl-u:删除到行首。这会少按好多 Backspace。Shift-PgUp,Shift-PgDn:在 terminal 中滚动。
禁用用户
有时需要禁用服务器某个用户,不让他登录。最好不要用 userdel -r
可以通过更改用户默认 shell 的方式让用户无法取得 shell 控制权,自然无法使用 服务器。更改用户 shell 的命令是 chsh。
1 | sudo chsh -s /sbin/nologin <username> |
/sbin/nologin 是一个特殊的 shell,这个 shell 会显示 This account is currently not available 后直接退出,从而“礼貌拒绝登录”。此时,该用户无法从 tty 或者是使用 ssh 进行登录。
假如该用户可以访问服务器上的其它用户(例如另一个用户是他的朋友,他只需要 临时借用他朋友的账号,这个用户不需要是管理员),那么他是可以通过朋友的账号 拿回自己的 shell 权限的。
1 | # user1 是被禁用账户,user2 是活动账户 |
这里看到,使用 su 命令可以对默认 shell 进行重写,这样我们做的工作全白费了。 使用 su 时需要密码,因此禁用 user1 的密码就可以避免这种方式的越权。
1 | sudo passwd -l user1 |
上面的命令实际上是修改了 /etc/shadow 文件的密码字段,使其失效。
要恢复账号,只需要执行下面两条命令。
1 | sudo passwd -u <username> # 解除密码的锁定 |
备注
使用 passwd -l 的原理是禁用用户密码,若用户使用了别的验证方式(例如 ssh 公钥),由于走的不是密码验证,因此禁用密码无效。
不能在远程 ssh 登录的时候复写登录用的 shell。如果能办到的话,很多安全措施 其实并不安全(例如 git-shell)。
GLIBC 版本错误
在旧系统(例如 CentOS 6)上安装一些较新的预编译的库,运行时可能会发生如下 错误
1 | >>> import torch |
原因是系统使用的 GLIBC 版本过低,里面的函数版本未达到要求。
GLIBC 的地位比较特殊,它不像其他的库只需要改动运行时目录就好。这是因为许多系统 的关键命令,例如 ls, cat,都依赖这个库。GLIBC 有许多模块,如果配置错误 导致各个模块的版本不相同,使用 GLIBC 的系统命令就会崩溃,进而整个系统会无法 使用,因此以管理员身份操作 GLIBC 时会非常危险。
传统的解决办法是拿到软件的源码然后重新编译一个,然而有很多因素阻止人们这样做:
重新编译需要解决很多依赖问题,且失败率较高,处理起来很费时。软件是闭源的,无法得到源码。软件编译时需要连网,而服务器无法访问某些网络。下面介绍一种直接修改二进制文件的方式,或许可以解决 GLIBC 的依赖问题。
处理一般的 GLIBC 版本错误是一个很难的问题,这里的方法不能确保一定成功。 笔者对 Linux 的 ELF 文件的理解也十分有限,不能确保下面所说的一定正确。
可执行文件依赖查找顺序
在执行一个可执行二进制文件之前,程序会将控制权交给一个特定的 loader,让它 解析程序文件的 header 并决定要载入哪些库。在 64 位 CentOS 6 系统下, 这个 loader 通常是 /lib64/ld-linux-x86-64.so.2。解析完成并加载程序所需的库 后,控制权回到原来的程序,程序正式开始运行。ld-linux 按照如下顺序查找依赖
ELF 文件的 DT_RPATH 字段,通常以 -Wl,-rpath 在连接时指定。已过时。 原因是它的优先级太高,一旦写死在文件里想临时更改并不容易(不过还是很多 人在用)。在 DT_RUNPATH 存在时将会被忽略。
LD_LIBRARY_PATH 中的路径。这是一个被“滥用”的环境变量,不过确实好用。 备注:当程序有 SUID 的时候这个变量将会被忽略。ELF 文件的 DT_RUNPATH 字段,以 -Wl,–enable-new-dtags,-rpath 指定。 据说 DT_RPATH 是个错误的设计,因此就出了 DT_RUNPATH。不过这个选项一些旧的 linker 可能不认识。
ld.so.cache 里的路径。
默认路径,例如 /lib64, /usr/lib64 等。除非程序编译的时候使用了 -z nodeflibs。
因为载入有顺序,同一个库即使被递归地依赖也不会载入两次。如果在一开始就强制载入 高版本的 GLIBC 库,那么之后遇到的 GLIBC 也自动会变成高版本的,这种办法就 可能解决问题。
查看 ELF 文件的依赖
ldd 命令可以检查 ELF 文件的动态库依赖关系(ldd 并不是个二进制程序,它只是 一个脚本,不信你用文本编辑器打开看一下)。例如
1 | $ ldd /bin/ls |
ldd 实际上调用的是 ld-linux-x86-64.so.2,这个程序根据上文中提到的顺序 对库进行查找。那么二进制文件如何找到 ld-linux-x86-64.so.2 这个 loader 呢? 这个 loader 的位置在编译的时候已经写死在二进制程序里了,不用找。 使用 readelf 命令可查看写死在 ELF 文件中的信息。
1 | $ readelf -d -l /bin/ls # -d 的作用是查看 dynamic 部分 |
有了 loader,程序的 header,依赖库的名字,程序运行前就能定出来它的依赖。
在工作站上安装软件
一般情况下,用户不能通过获取 root 权限的方式安装软件。不过,一般的软件都可以通过一系列 设置安装到自己的个人目录下。通过这种方式安装的软件只能自己使用。
例子:从源码安装软件 FFTW
大部分源码安装的软件都需要进行以下三步
- configure: 设置,用户需要根据需求选择软件中的安装选项以及功能
- make: 编译,使用系统的编译工具将源码编译成可执行的文件或库文件
- install: 安装,将编译好的文件安装到指定的位置
在安装之前,用户需要自行处理软件的依赖,这可能是个复杂的过程,不过 绝大多数数软件的依赖都已经满足。如果需要帮助可联系管理员。
在安装结束后,用户需要设定环境变量,以便可执行程序,库文件,帮助文档 可以被正常访问。通常需要改动的变量是 PATH,LD_LIBRARY_PATH 等。
首先从官网下载 FFTW 的源码。在这里我们以 3.3.5 版本为例。假设下载的文件储存在 服务器个人目录下,文件名字为 fftw-3.3.5.tar.gz。
- 首先,使用解压缩命令将源码文件解包。
$ tar -xzf fftw-3.3.5.tar.gz - 解包完成后会得到一个名为 fftw-3.3.5 的文件夹,我们需要切换到这个文件夹内。
$ cd fftw-3.3.5 - 在这里我们新建一个名为 build 的文件夹,以储存所有编译的中间文件。不建议直接在 源文件的目录进行操作,因为在执行编译结束后无法分清哪些是编译生成的文件,会给清理 造成麻烦。
$ mkdir -p build && cd build - 接下来,调?? configure 脚本进行设置
$ ../configure --prefix=$HOME/local - 其中的 –prefix 参数一定要设置,它是指定了软件的安装位置。如果不指定,则实际安装的时候 会安装到系统目录中去,由于 一般用户不具备操作系统目录的权限,所以安装过程会失败。其他的选项 根据需求安装即可,在这里我们均使用默认值。
- 如果软件的依赖全部满足,则 configure 会正常结束,并在当前的目录下生成 Makefile 和 config.log 等文件,这时候就可以进行编译了。使用make命令进行编译编译需要进行一段时间,对于有些软件的编译过程非常漫长。
$ make - make 命令正常结束后,需要使用
$ make install - 将软件安装到指定的目录下,在这里我们是把软件安装到 HOME/local 目录下。安装完成后,可以在 HOME/local 目录下 看到多出了 include lib 等文件夹,这就是我们软件的实际文件了。
如果有必要,需要在 .bashrc 中修改环境变量,以便在使用软件的时候系统可以在正确的路径找到 我们的库。
小提示
安装完毕后,原则上不再需要软件源码和产生的中间文件。但是建议保留这些安装文件,以便在软件出问题 的时候进行重新安装,或者是在不需要的时候将其删除(删除软件的命令写在了 configure 生成的 Makefile 中)。
安装 Python 包到个人目录
在运行 python 等程序时经常需要各种 python 的软件包,这些包有的已经安装在服务器中了,有些则没有安装。出现这种情况可以联系管理员进行安装,或者可以自行将所需要的包安装在自己的 HOME 目录下。
使用 pip 安装
使用 python 自带的 pip 包管理程序可以方便地进行安装,但是默认情况下 pip 将软件包安装到系统文件夹下,普通用户没有这个权限。因此需要指定 pip 将包安装在 个人的 HOME 目录下。
$ pip install <package name> --user
这里 package name 是所需包的命令,重要的是后面 --user 这个参数,它表示单独为当前用户安装这个 python 软件包。安装的位置是
~/.local/lib/python<ver>/site-packages
其中 ver 是对应 python 的版本。这样安装过后,对应的包就可以使用了,并且不会影响服务器上的其它用户。
使用 conda 安装
如果你在使用 anaconda,那么除了以上的 pip 管理器,你还可以使用 conda 命令进行安装。使用的方式为
$ conda install <package name> --prefix /path/to/install
这里重要的是 --prefix 参数,它指定了相应包的安装路径。在这里建议使用的路径依然是
~/.local/lib/python<ver>/site-packages
其中 ver 是 anaconda 内部嵌入的 python 版本,这样 python 可以在对应位置找到所需要的包。
使用 conda 创建环境后安装(推荐)
conda 除了可以直接安装包以外,还可以创建独立运行环境并且只将指定版本的包安装 到环境里。这和 virtualenv 功能相似。独立环境可以较好地解决 python 包之间版本 依赖问题,并且完全不需要管理员权限。推荐多数用户使用
在工作站和 PC 间传输文件
我们经常会将我们本地的一些文件上传到工作站上,或是从工作站下载文件。这些工作用命令行可以轻松完成。
建议在传输文件之前对要传输的文件进行打包,以便有更高的传输效率。在 Linux 下可以使用 tar 工具进行打包。
$ tar -cjf archive.tar.bz2 folder1/ folder2/
上面的命令是将两个文件夹下的所有文件打包到 archive.tar.bz2 文件中,并进行一定压缩。在工作站打包数据建议使用这个命令。
Windows 用户可以使用 WinRAR 或者 Zip 进行打包。
在服务器中,相应的解包命令为
1 | $ tar -xjf archive.tar.bz2 |
Linux 或 Mac
使用 scp
在命令行中可以使用 scp 命令进行传输文件。这是依赖于 SSH 的一个命令,如果已经配置了 SSH 无密码 登录那么每次复制将不必输入密码。否则,每次传输文件都需要输入密码。
以下命令均在本地计算机中执行。
1 | $ scp file username@ip_address: |
上面的第一条命令即可将 file 传输到工作站相应账号的 HOME 文件夹下,如果想要指定目录,可以直接写 相对于 HOME 文件夹的路径,例如第二条命令。
如果要使用 scp 命令复制文件夹,需要加上 -r 参数。
$ scp -r folder username@ip_address:
从服务器传输文件到本地只需将两个参数的位置调换。
$ scp username@ip_address:file .
在这里我们使用 . 来表示本地的当前路径。
####使用 rsync
rsync 是强大的同步文件的命令行工具,它比 scp 更加智能。rsync 支持从本地到本地, 从本地到服务器,从服务器到本地的文件传输。使用 rsync 访问服务器依赖于 SSH 的 配置。下面的例子假定用户已经配置了 SSH 无密码登录。
#####传输文件
rsync 基本的传输文件命令为
1 | # 下载文件 |
其中 SRC 表示来源的路径,DEST 表示目标路径。由于要访问服务器,因此当来源或 目标不是本地时,需要指定服务器的用户和主机名。用户和主机名的指定可以直接使用 SSH 的 .ssh/config 表示的格式。
因此上传可用
1 | # 假设已经配好了 SSH config,server 表示的主机有意义 |
其中的三个选项,a 表示归档模式,在这个模式下传输将递归地进行,并保留文件的 权限信息;v 表示将中间信息输出;z 表示在传输过程中进行压缩来减少传输量。 下载只需要将 SRC 和 DEST 的地位对换。
rsync 的优势在于,每次在传输之前会对文件进行比较,只会传输那些真正改变的文件, 在多数情况下会极大减小传输量。下面是一个例子。
1 | [mcc@laptop ~]$ ls test/ |
#####同步时删除
使用 rsync 上传文件时,如果 SRC 的文件比 DEST 的文件要少时,rsync 默认不会去 处理 DEST 多出来的文件。如果要实现真的的完全同步,即删除 DEST 多出来的文件,需要 给 rsync 加上 --delete 选项。
接着上面的例子,在本地删除 1.txt,并告诉服务器也要删除这个文件
1 | [mcc@laptop ~]$ rm test/1.txt # 删除 1.txt |
断点续传
rsync 的同步算法只能针对整个的文件。默认情况下,如果文件传输不完整,rsync 会 扔掉这些文件,在下次传输的时候重新处理。当要传输单个大文件时,由于网络等多方面 原因,传输很难一次完成,这时候就需要断点续传功能。
1 | # 使用 rsync 指定 --partial 选项来保留传输未完成的文件 |
Windows
使用 WinSCP 图形客户端。下载地址
- 在下图中分别输入服务器IP,用户名,密码。
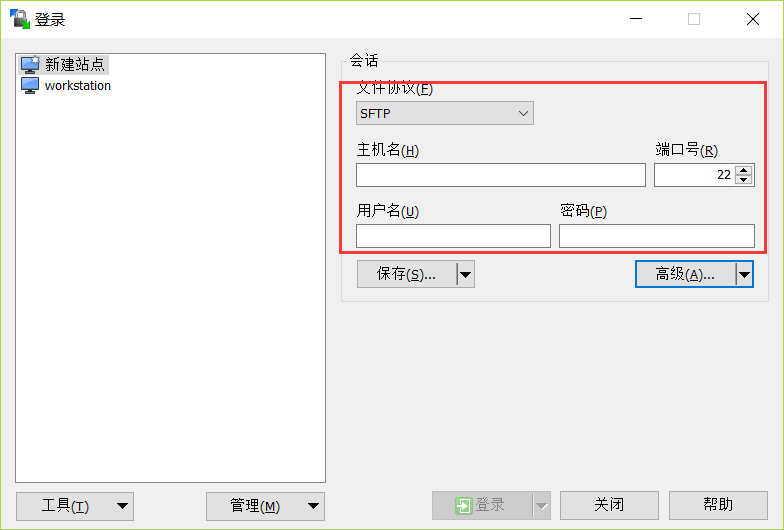
在 WinSCP 中同样可以配置 SSH 无密码登录,点击“高级”即可进行类似设置(需要 ppk 文件:生成方法)。
- 进入传输面板进行操作即可。
使用图形界面
通常情况下,在集群中我们都在命令行中操作。但是有时我们需要打开某些软件的图形 界面,此时我们需要借助 X11 转发。
注意:在网络不好的时候请谨慎使用此功能,此时经过 X11 转发的界面操作起来有 明显卡顿。尽量在校内有线网或信号较好的无线网的环境下使用。
Linux
在 Linux 环境中启用 X11 转发非常简单,只需要在登录时加入 -X 参数。
mcc@pisces: $ ssh -X user@server_ip
此后登录集群可以直接输入命令开启图形界面的程序。例如
[mcc@pisces ~]$ display
MacOS
使用 MacOS 系统时需要安装第三方支持 X11 的软件 XQuartz。
安装完毕后,在登录集群时加入 -X 参数。
mcc@pisces: $ ssh -X user@server_ip
此后登录集群可以直接输入命令开启图形界面的程序。
Windows
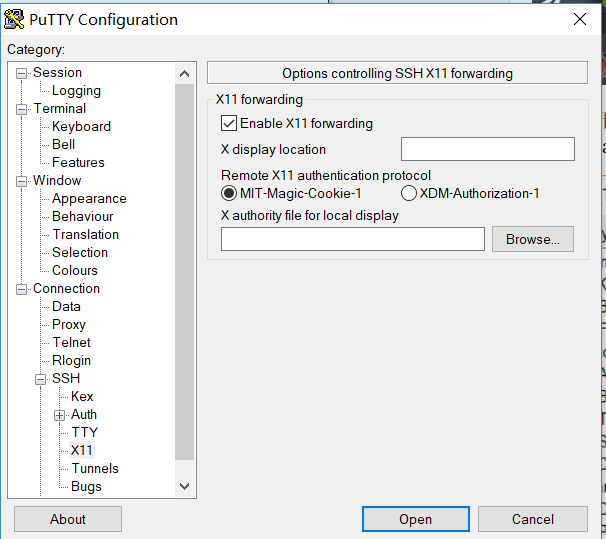
使用 PuTTY 配合 Xming
PuTTY 用户可配合 Xming 软件完成 X11 的转发。
首先下载 Xming。
安装完成后双击 Xming.exe 打开 Xming 的 Xserver,此时会在系统任务栏的 右下角看到 Xming 正在运行。
然后打开 PuTTY 客户端,选择服务器的相应 Session 配置,点击 Load 载入这个配置。 在左边面板选择 SSH -> X11,在右边勾选 Enable X11 Forwarding。 最后回到 Session 界面点击保存即可。